
I’m Kangwei Liu (刘康威), a Ph.D. candidate in Institute of Information Engineering, Chinese Academy of Sciences (IIE, CAS), under the tutelage of Prof. Xianfeng Zhao and Associate Prof. Yun Cao. My research interests include Audio-driven Talking Face Generation and Facial Animation.
I received my B.E. degree from College of Computer Science and Engineering, Northeastern University and was mentored by Prof. Peng Cao at NEU.
I am open for collaborations in research, especially in the fields of Audio-driven Talking Face Generation and Facial Animation. Please feel free to contact me.
🔥 News
- 2025.03: 🎉🎉 Two first-author papers accepted by ICME 2025 (CCF B)!
- 2025.03: 🎉🎉 One first-author paper accepted by IJCNN 2025 (CCF C)!
- 2024.03: 🎉🎉 One first-author paper accepted by ICME 2024 (CCF B, oral)!
- 2023.05: 🎉🎉 Won 2nd place in “天马杯” National College Science and Technology Innovation Competition (20,000 RMB Award).
📝 Publications
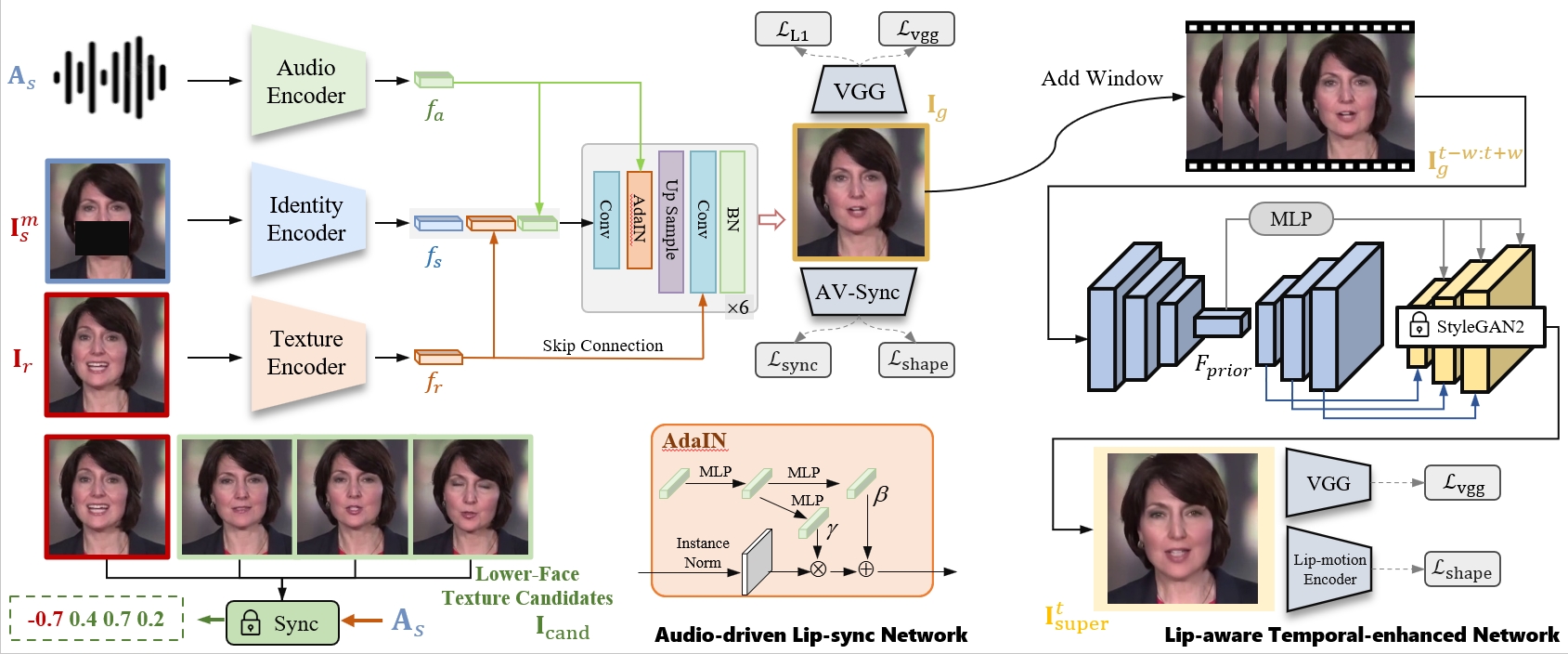
ProDub: Progressive Growing of Facial Dubbing Networks for Enhanced Lip Sync and Fidelity
Kangwei Liu, Xiaowei Yi, Xianfeng Zhao
- TL;DR: A progressive framework for facial dubbing that disentangles mouth shape and texture for better lip-sync, while enhancing visual quality through a lip-aware temporal network. Improves lip-sync by 10.7% and visual quality by 28.5% over SOTA methods.
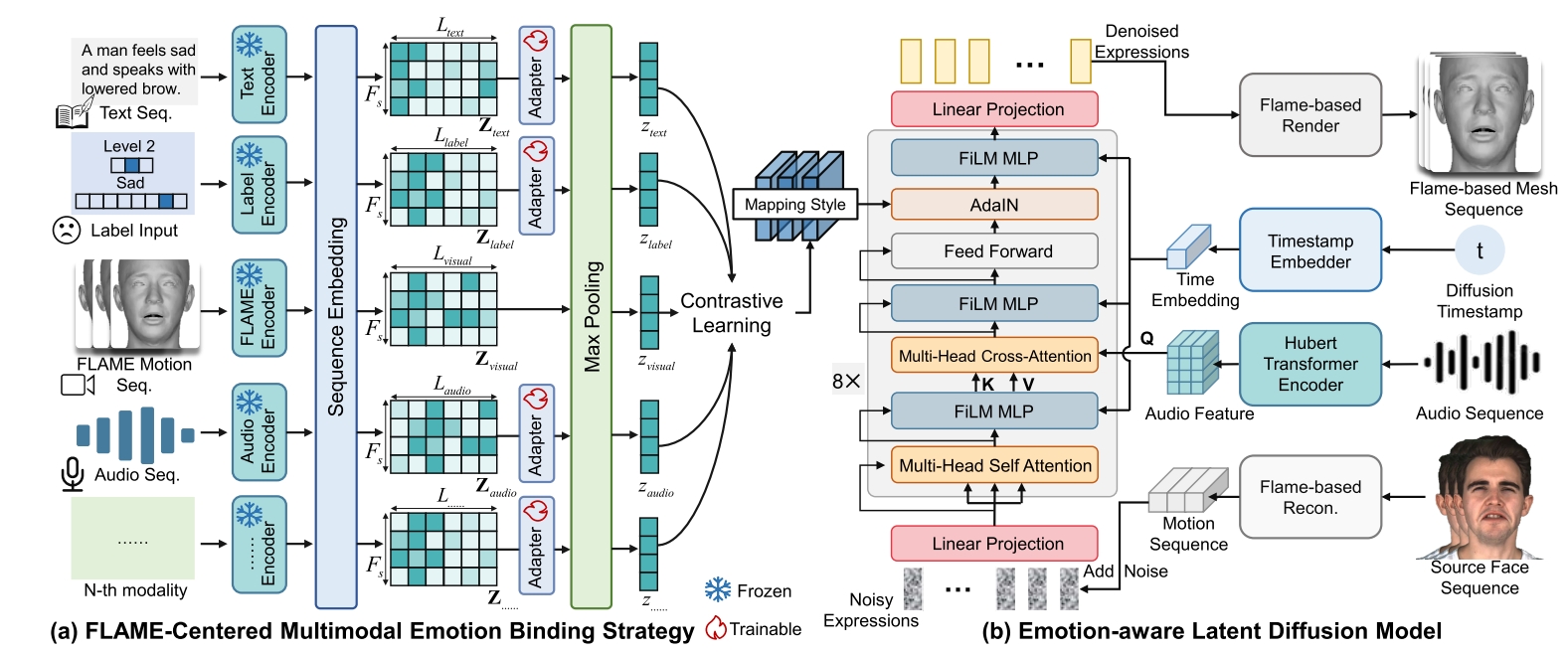
Controllable Expressive 3D Facial Animation via Diffusion in a Unified Multimodal Space
Kangwei Liu, Junwu Liu, Xiaowei Yi, Jinlin Guo, Yun Cao
- TL;DR: A diffusion-based framework for 3D facial animation that unifies multiple control signals (text, audio, emotion labels) and generates diverse, temporally coherent facial expressions, achieving 21.6% improvement in emotion similarity while maintaining natural dynamics.
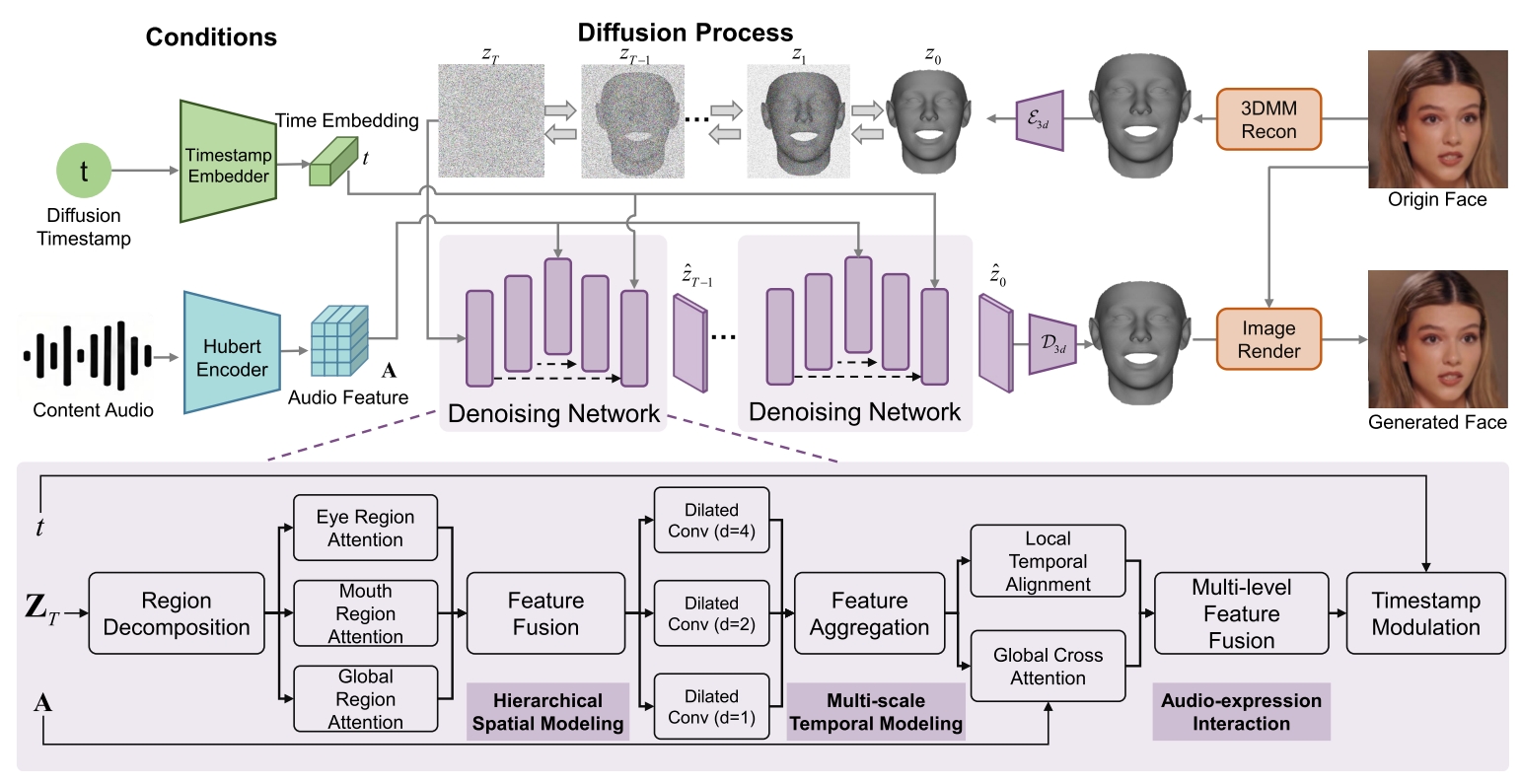
DisentTalk: Cross-lingual Talking Face Generation via Semantic Disentangled Diffusion Model
Kangwei Liu, Junwu Liu, Yun Cao, Jinlin Guo, Xiaowei Yi
- TL;DR: A novel approach that decomposes 3DMM expression parameters into meaningful subspaces for fine-grained facial control, enabling cross-lingual talking face generation with superior lip synchronization, expression quality, and temporal consistency.
🎖 Honors and Awards
Graduate Studies
- 2024: Outstanding Student Cadre of University of Chinese Academy of Sciences (UCAS)
- 2023: 2nd Place in “天马杯” National College Science and Technology Innovation Competition (20,000 RMB Award)
- 2022-2024: Outstanding Student of UCAS
- 2021: UCAS Scholarship
Undergraduate Studies
- 2020.12: China National Scholarship, Ministry of Education of the People’s Republic of China (Top 1.5%), NEU
- 2020: Mayor’s Scholarship of ShenYang, China (Ranked 6 out of 4000+)
- 2018-2020: Northeastern University First-Class Scholarship (Ranked 1/268, 3/268, 2/317)
- 2018-2019: Northeastern University “Outstanding Student Model” (Top 1%)
- National Second Prize in China Undergraduate Mathematical Contest
- Second Prize in International Mathematical Modeling Contest (MCM)
📖 Education
-
2021.09 - 2026.06 (expected), School of Cyberspace Security, University of Chinese Academy of Sciences, China.
Ph.D. Candidate -
2017.09 - 2021.06, College of Computer Science and Engineering, Northeastern University, China.
Bachelor of Engineering
Ranking: 14/268
💬 Invited Talks & Teaching
- 2024-2025: Delivered 9 science popularization lectures on facial deepfake technology to primary and secondary schools in Beijing (Zhongguancun No.1 Primary School, Beijing Foreign Studies University Affiliated School, CAS Qiyuan School, etc.)
- 2024.07.18: Gave an oral presentation at ICME 2024 conference in Niagara
- 2023.11: Presented deepfake content generation technology at the National Defense University Academic Forum
- 2023.06: Presented deepfake content generation technology at the Military Science Academy Academic Forum